Korrektur 2009-08-24: Es ist äußerst peinlich, aber Senayan stammt natürlich nicht aus Indien, sondern aus Indonesien. Der Titel ist nun korrekt, Inhalt angepasst, aber der Permalink bleibt lieber mal. Lesson learned: niemals müde und mit Kopfschmerzen auf Veröffentlichen klicken (oder überhaupt schreiben).
Beim Beitrag Bibliothekskataloge/OPACs für alle? erwähnte ich am Ende, dass ich noch ein ziemlich schickes System gefunden habe, denn ja, ich habe tatsächlich bei Sourceforge nach Perlen getaucht. Mit Senayan kommt somit noch ein Open Source Library Management System aus Indonesien hinzu, das definitiv Aufmerksamkeit verdient. Die Version bei Sourceforge ist gegenüber der Version auf der offiziellen Seite veraltet. Anscheinend sind die Entwickler zu Github (“Social Coding”) übergegangen.
Es ist das einfache, überall lauffähige und dabei relativ mächtige Bibliotheksmanagementsystem, das ich im oben genannten Beitrag gesucht habe. Es wäre müßig, wenn ich jetzt alle Features aufzählen würde, denn diese werden auf der Senayan-Seite bereits genannt – zugegeben kribbelt es bei Kardex, Z39.59 und Zweigstellen doch unter den Fingern, diese zu erwähnen. Auf der Seite sind aber auch eine Demo-Version, sowie Screenshots verfügbar. In den Adminbereich der Demo kommt man mit admin als Benutzername und Passwort. Wer gleich richtig durchstarten will, der kann sich auch eine portable Senayan-Version holen (rechts unter Releases), die von Fandi Gunawan entwickelt wurde (Portable Senayan : Open Source Library management System is now portable). Aber dafür hab ich ja meinen Uniform Server bereits 🙂
Hier ein paar Bilder meiner Installation
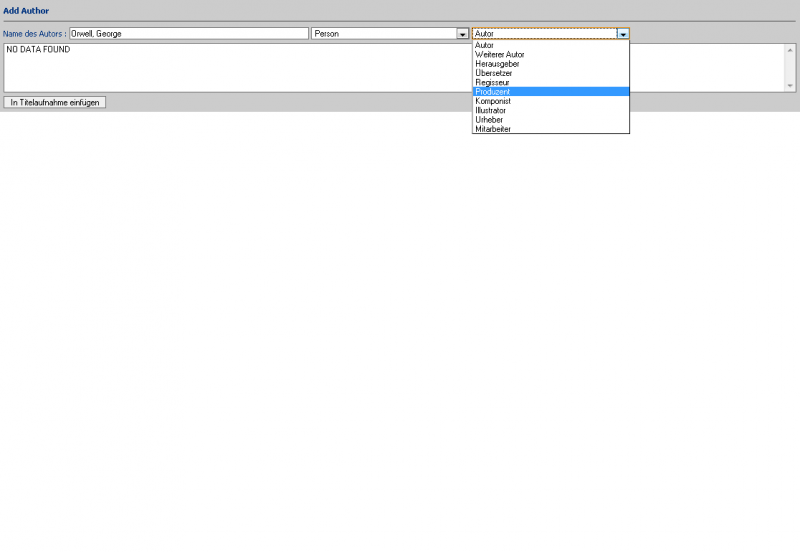
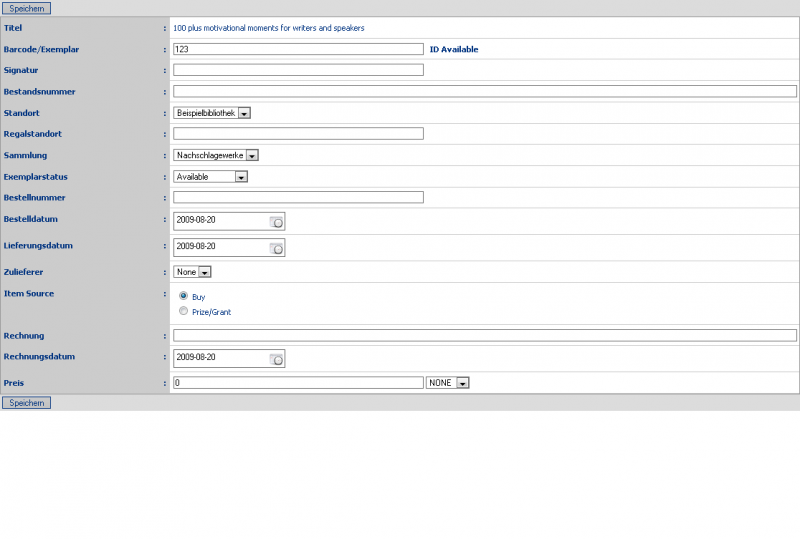
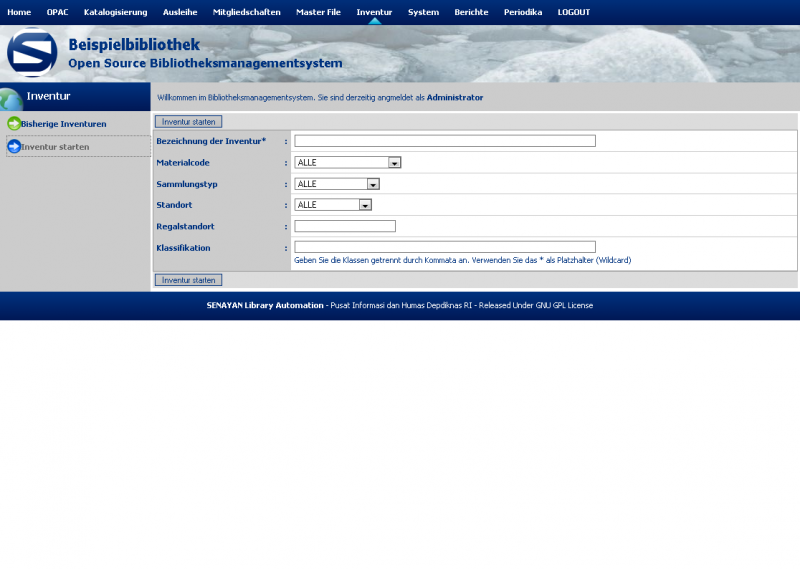
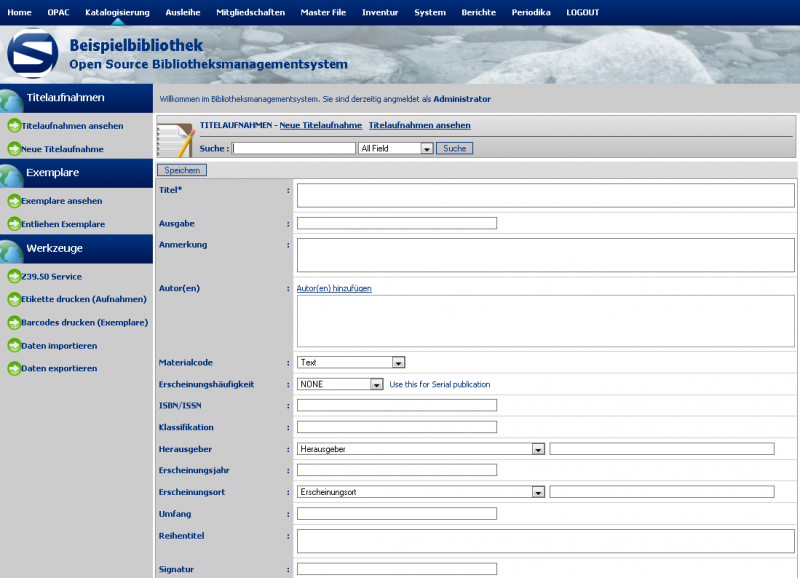
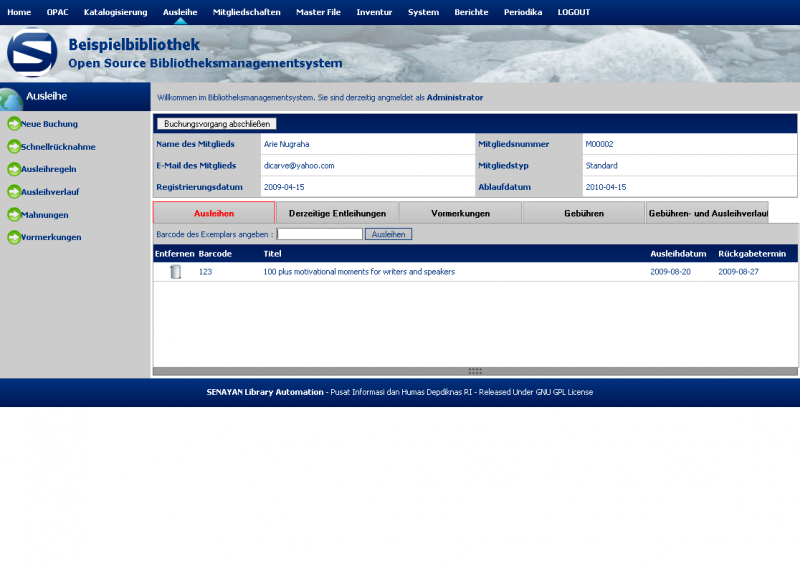
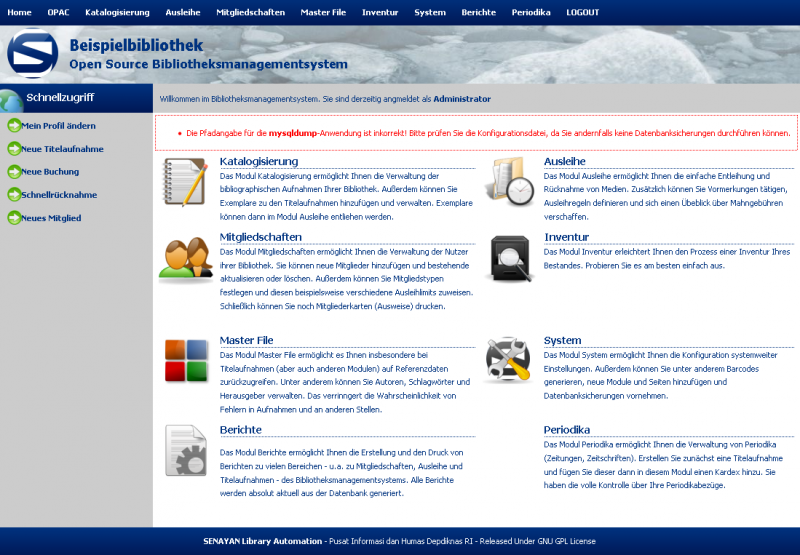
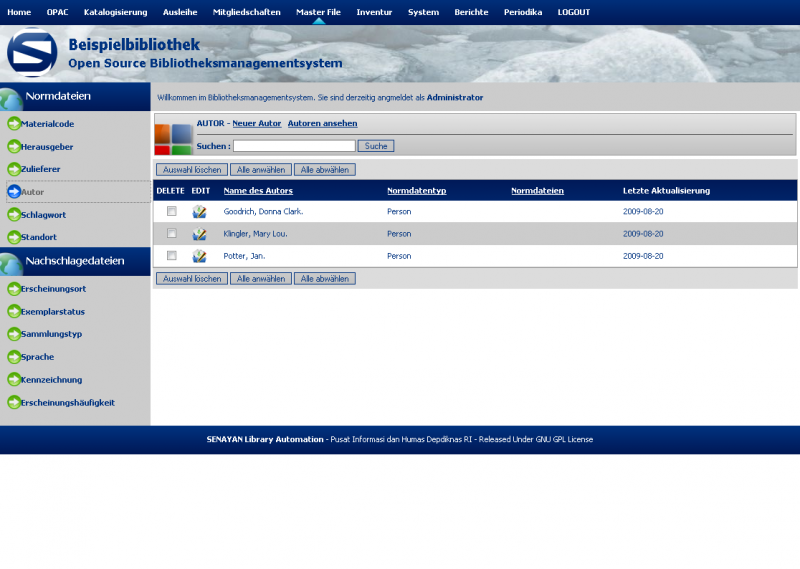
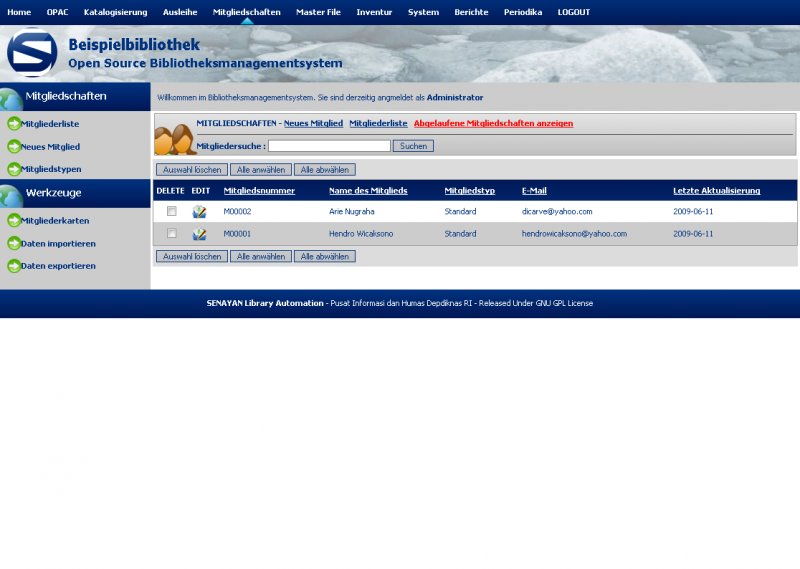
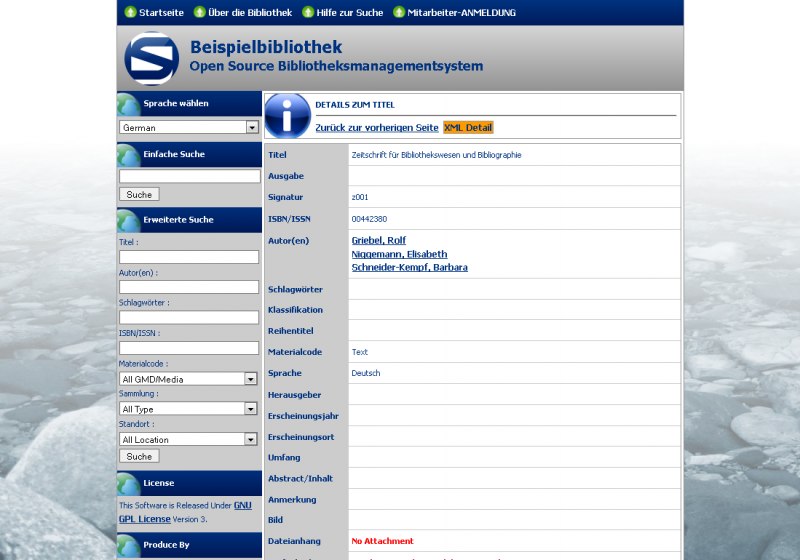
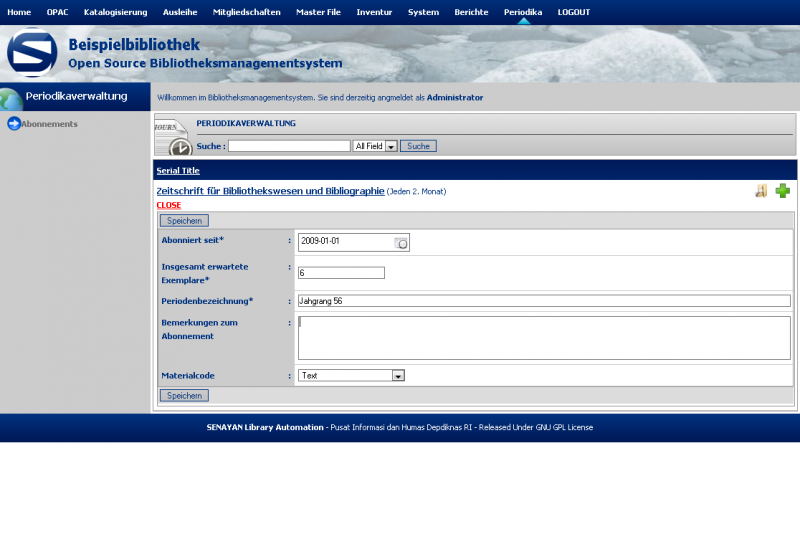
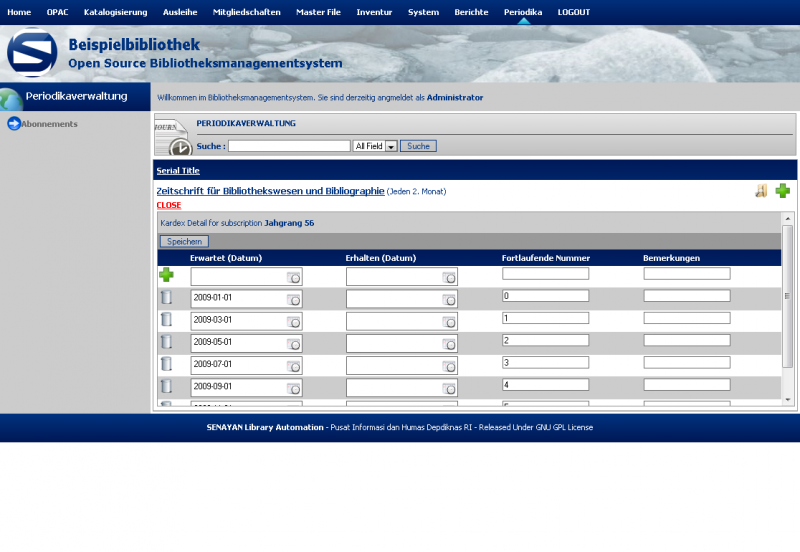
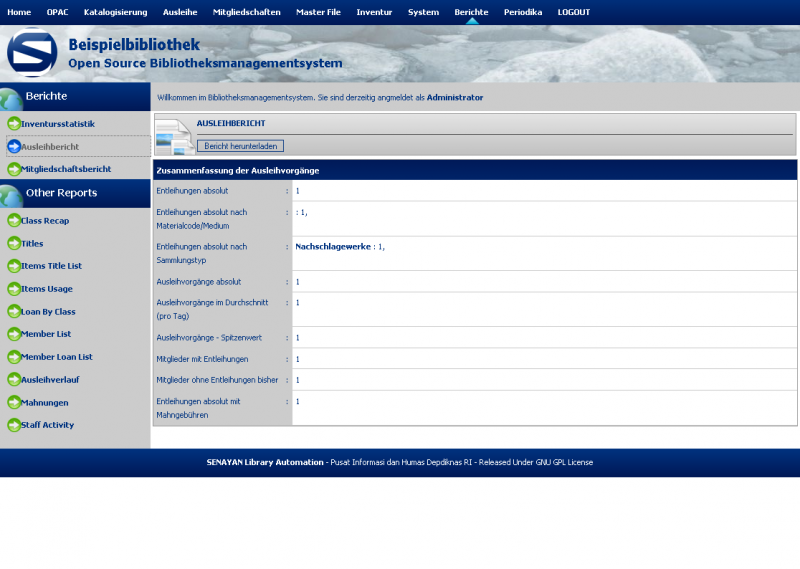

Einen kleinen Haken hat die ganze Sache allerdings: Ein Katalog auf Englisch oder Indonesisch bringt in Deutschland nicht viel. Da ich wirklich sehr angetan von dem System war, hab ich mich mal an eine Übersetzung gewagt, wie man bei den Bildern sieht. Dabei habe ich festgestellt, dass leider für einige Stellen keine Übersetzungsmöglichkeiten (von Englisch) angeboten werden, aber hauptsächlich betrifft dies Berichte im Adminbereich. Da Senayan aber noch (sehr) aktiv entwickelt wird, wäre ich zuversichtlich, dass auch dies korrigiert wird.
Insgesamt hat die Übersetzung etwas mehr Zeit in Anspruch genommen als ich dachte. Ganz glücklich bin ich auch nicht damit, aber es ist ein Anfang. Da ich erst mal herausfinden muss, an wen ich die jetzt schicken kann (bei der alten Sourceforge-Version einchecken scheint mit wenig sinnvoll; Github bin ich mir unsicher), hänge ich den “Deutsch-Patch” erstmal an diesen Beitrag an. Die Schritte wären dann:
- Senayan runterladen und entpacken
- Den Patch herunterladen (senayan3-(s10,p1)_german-patch) und an die selbe Stelle entpacken
- Fünf-Schritt-Anleitung install\README-german.txt lesen
- (Mit ein klein wenig Routine bei sowas, läuft das ganze in fünf Minuten)
Tja, was bleibt noch zu sagen? Wer nach ein Bibliotheksmanagementsystem für zum Beispiel eine Schule oder ein Projekt, das nicht gleich der Nationalbibliothek Konkurrenz machen will, sucht, aber vielleicht Aufwand und Anforderungen (~Kosten) von Koha scheut, sollte sich Senayan mal ansehen. Senayan sollte auf jedem “billig”-Webserver laufen und schlägt die Favoriten dieser Liga – von den Downloadzahlen her; OpenBiblio und PHPMyLibrary – um Längen. Gerade mal 800 Downloads ist aber auch eine Schande (hmm, bei der Strahlweite dieses Blogs wird es jetzt wohl auch nicht besser :D). Einzig wird wohl dort die Z39.50-Unterstützung (YAZ) fehlen, die aber nicht zwingend notwendig ist (sprich eine Installation verhindert). Dann muss man eben von Hand katalogisieren, obwohl auch eine Importfunktion geboten wird – wenn man die Daten also anders bekommt…
Als Open Source ist es natürlich auch wegen der Kosten einen Blick wert. Wenn ich das nicht misinterpretiere, ist Senayan übrigens unter Schirmherrschaft des Department of National Education/Indien entstanden – da gibt’s sowas als gefördertes Open Source, bei uns höchstens ein “kostengünstiges” Allegro-C? In diesem Zusammenhang sind auch insbesondere die Kommentare zur Infobib-Meldung Erste norwegische KOHA-Installation interessant.
Bei allem Lob, es gibt es auch Schwächen. Allerdings habe ich hier natürlich kein Produktivsystem, von daher kann ich da keine grundsätzlichen Aussagen zu Stärken und Schwächen treffen, allerdings scheint es in Indonesien sehr beliebt zu sein, sich also bewährt zu haben. Wirklich schade fand ich vor allem, dass eben keine vollständige Übersetzung möglich ist. Bei den Titelaufnahmen hat mit gewundert, dass kein Feld für den Untertitel vorgesehen ist. Andererseits ist die Suche aber ziemlich gut und irgendwie ist es dann auch egal (das meine ich jetzt natürlich nicht wirklich lieber potentieller Arbeitgeber ;)). Auch wäre es natürlich schön, wenn man noch andere Z39.50-Server als den der Library of Congress wählen könnte (mal sehen, ob ich das in den nächsten Tagen herausfinde wie’s auch mit dem GBV klappt), aber das ist auch kein echter Minuspunkt. Theoretisch wäre das Fehlen einer (englischen) Dokumentation ein negativer Punkt, von meiner Seite allerdings auch nur eine halbherzige Kritik, da ich das ganze System eigentlich ziemlich intuitiv fand – 102 Seiten Doku, ob englisch oder indonesisch – sind so oder so doch wenig attraktiv.
Vielleicht reizt es jetzt nun aber noch jemanden Senayan mal zu testen. Vielleicht dann etwas kritischer? 😉
4 Antworten zu “Senayan – Open Source Library Management System aus Indonesien”
Das eprint hier: www.eprints.org oder etwas anderes? Für Leihverkehr scheint mir das nun gar nicht geeignet. Es kommt halt auch immer drauf an, was man braucht. Bei irgendwas hakt es immer, sei es beim OPAC oder beim Leihverkehr oder…
Bei 1000 Titeln, die sowieso vor Ort durchgesehen werden, würde ich vielleicht auf BookCollector (www.collectorz.com/book/) setzen, weil man damit auch die Übersicht über (eine überschaubare Menge von) Ausleihen behalten kann und es sonst ziemlich bequem zu handhaben ist.
Mit Senayan, was es nun übrigens hier gibt slims.web.id/web/, könnte ich mich auch gut anfreunden, das aber auch, da ich es halt besser kenne…
ich sehe mich auch gerade für einen Verein mit mehr als 1000 Büchern um. Koha ist wohl das Gesuchte…die Installation ist ja nicht so schwer. Gut Plugins und Customizing macht Arbeit. vorausgesetzt ich finde noch jemanden, der schon etwas Erfahrung mit koha gesammelt hat. aber ein Freund, der in einer Biblio arbeitet, meinte, ich sollte mit “eprints” anschauen. das kann man ja auch für normale Bücher nehmen. ich prüfe das gerade. was meinst du?
Die z39.50-Schnittstelle ist eigentlich ziemlich simple. Theoretisch kann man ganz einfach viele weitere Server eintragen die nach und nach abgefragt werden – das ist bereits im Quellcode vorgesehen (\senayan3\admin\modules\bibliography\z3950.php; Zeile $zserver[] = ‘z3950.loc.gov:7090/voyager’; suchen).
Das Problem ist, dass beim GBV-Server immer die Meldung “bad use argument” oder so ähnlich kommt (immerhin kommt schon mal eine Antwort). Ich habe mir den Aufbau von z39.50-Anfragen allerdings jetzt nur kurz angesehen, wollte das aber nochmal die Tage über angehen.
Eine (umfassende) Dokumentation wäre sicher wünschenswert und ich habe schon mit dem Gedanken gespielt dafür ein Wiki zu missbrauchen. Eigentlich scheint mir das aber erst sinnvoll, wenn das System wirklich vollständig eingedeutscht (bzw. übersetzbar) wäre.
Die fehlenden Übersetzungsmöglichkeiten zu ergänzen wäre somit der aktuelle Gedanke mit dem ich spiele. Ich muss allerdings erst mal rausfinden, wie das mit dem Ein- und Auschecken (bei Sourceforge) überhaupt funktioniert. Und der Versionierung allgemein…
Etwas eigenwilliger Weise haben die Entwickler die aktuellsten Versionen aber bei Sourceforge gar nicht mehr eingestellt, sondern managen u.a . das Bugtracking über ihre eigene Seite. Hmm, na mal gucken, ob ich doch mal irgendwen erreiche. 🙂
Applaus, applaus! Wieder ein System mehr, dass zumindest theoretisch dem deutschen Markt zur Verfügung steht.
Zu Z39.50: Kann man die Schnittstellen einfach nachtragen?
Was ich leider sagen muss: Eine fehlende Doku oder eine in einer in Deutschland nicht gängigen Sprache wäre für mich in der Praxis übrigens ein Ausschlußgrund.
PS: Die Übersetzung würde ich auf jeden Fall in Sourceforge nachtragen, damit die Entwickler sie gleich weiterverteilen und berücksichtigen können.